Genetic Resources Repository Collections Integration
Established in 2006, the Florida Museum’s Genetic Resources Repository (GRR) archives more than 60,000 tissue samples and DNA and RNA preparations derived from physical specimens in the Museum. The GRR is a unique collection in the Museum in the sense that it holds data referring to other collections’ specimens. As such, the genetic samples’ taxonomy, collecting information, etc., are all subject to change in the samples’ source collections. In order to correct for possible data anomalies or incongruities, OMT has implemented a system to insure that the source collections’ current data flows back into the GRR on a regular schedule.
Through a combination of tools available in the Specify collections database software suite and scheduled shell scripts the data is kept in sync. This workflow consists of three main components:
How to Submit Data to the GRR
The submitting collection must first create preparations in their Specify database for the collection objects that are being sampled. A typical prep type assigned to this preparation is Tissue Sample, but the name may vary according to the needs of the source collection.
The submitting collection then populates a Specify workbench spreadsheet template with data describing an accompanying batch of sample submissions. This spreadsheet contains the necessary data to enable the scheduled update.
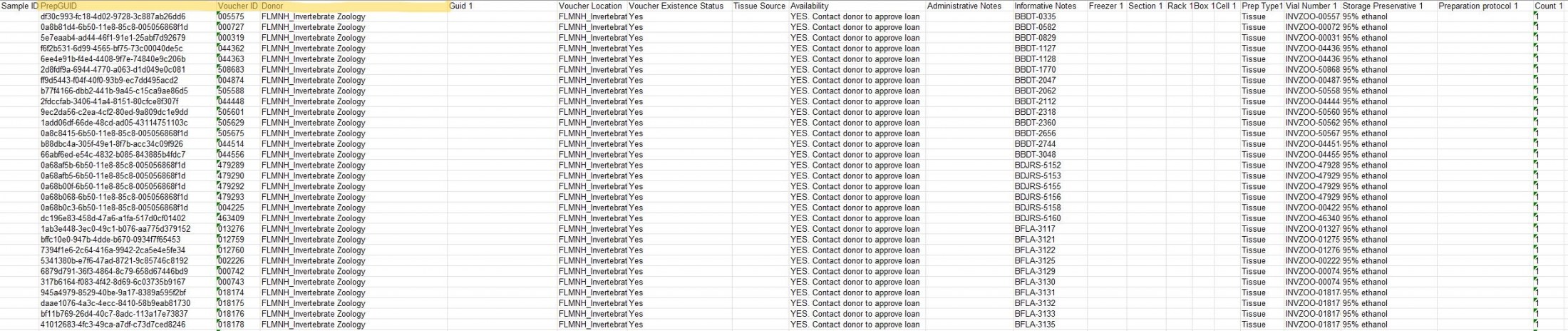
The highlighted columns, as seen in Figure 1, are the columns that enable the linking of the specimen data to the source collection.
- SampleID – this is the submitting collections’ internal tracking number
- PrepGUID – the GUID for each sample’s corresponding Preparation in the source database.
- VoucherID – the catalog number for the collection object that the sample’s preparation belongs to.
- Donor – the name of the submitting collection. The donor value must be one of the values below:
- FLMNH_Herbarium
- FLMNH_Herpetology
- FLMNH_Ichthyology
- FLMNH_Invertebrate Zoology
- FLMNH_Lepidoptera
- FLMNH_Mammals
- FLMNH_Molecular_Lab
- FLMNH_Ornithology
Once the data spreadsheet is filled and the samples are ready to submit, the submitting collection’s staff contacts the GRR Collection Manager, Terry Lott, and arranges for him to receive the samples and spreadsheet.
The GRR Collection Workflow
The GRR collection’s staff then receive the genetic samples and data and begins processing them. As the samples are placed in the cryo-freezer, the storage location columns, as seen in Figure 1, are populated. The spreadsheet is then ingested by the Specify workbench. This creates a collection object and an associated Tissue preparation in the GRR database for each row in the spreadsheet. Figure 2 shows a typical GRR collection object. Note that the Col Obj Attribute section is initially unpopulated and has no corresponding columns in the spreadsheet shown in Figure 1. These values are populated in the subsequent scheduled server sync process.

The Scheduled Server Sync Process
In order for the GRR database to contain the newest and most accurate collections data, a data sync process must occur between the GRR and the submitting collection’s databases.To complete this data sync, a scheduled process runs on the database server at a regular interval. This process uses the PrepGUID in the GRR collection object to find the corresponding collection object in the submitting collection’s database. It then populates each collection object in the GRR with the values from the source collection. Those values are all displaying in Figure 2 under the Col Obj Attribute section. In this way, changes in the source collection’s data are automatically reflected in the GRR database.